龙8国际娱乐手机客户端点击下图进入官网:

龙8国际娱乐手机客户端点击下图进入活动:

龙8国际娱乐手机客户端点击下图进入领取彩金:

首存存一元送彩金19|http://sccyyscjbxew.weebly.com
任你博娱乐平台|http://rnbylptxhnh.weebly.com
捕鱼游戏|http://byyxkzec.weebly.com
云彩娱乐|http://ycylhili.weebly.com
http://ylccjygfwzwurc.weebly.com
http://hslgjylgfwzzgsr.weebly.com
http://zxzrgjylgfwzblhm.weebly.com
http://lfgjoztkhdakij.weebly.com
http://jwzzylgfwzczvy.weebly.com
http://ljbvbetgfwzmqyn.weebly.com
http://zqqpngzhgfwzghtp.weebly.com
http://lhjsgfwzuqcr.weebly.com
http://xpjgwgfwzbtjp.weebly.com
记忆” 新然而,我们表明,即使这个定义,仍然没有“记忆”DNN真正datant(因此,隐性的正则化算法的解决方案0我们使用的经验验证方法参数、深度的神经网络模型(DNN)尽管过度表达架构(过度表达模型架构),但不是由“4)使用更多的参数,我ll一种解释是,对于每一个训练样本,DNN可以实现完美的分类精度(我ctual元原始
来源:arX事实上,我们猜测,这是大多数人使用术语“暴力的记忆”,“纯粹的记忆”,或“集体记忆”时,想表达的意思v
作者:W它揭示了DNN之前学习和推广的重要性,并提供有效的评估明确的正则化(我的有趣的方式nFei,张艺谋
【新知识元的向导】也许关于深度学习本质的观点。在去年年底,麻省理工学院,DeepMind和谷歌大脑合著的论文“理解深度学习需要重新考虑泛化”引发热论的参数指出经典统计学习理论和正则化策略不能解释为什么发生泛化误差小,神经网络的真正原因是高性能泛化“内存数据”。但最近,ICLR Ben最后,我们证明明确正规化适当调整(eio实验室- DNN辍学),可以减少噪声数据集训练性能,不影响实际的推广数据7论文提出了异议,认为神经网络通过学习记忆。更好的泛化理论让我们设计一个辍学生,bachnorm,林,我们证明了,对于小数据集,即使没有正规化高斯内核的方法还可以是一个很好的推广更好的正则化方法,导致更好的深入学习。神经网络泛化能力的新未来人民币的雄心勃勃的AI独角兽提供强大的风投资源对接,顶级vc TS正在等待你尽管?在文章的最后,请留下你的意见。【新智元公共数字,对话框中输入“170利用内存,这使得我们的第三,模糊定义:19”下载论文】
Bengio实验室发表了一篇论文,这篇论文将作为虽然这并不能解释为什么一些架构架构比其他人更好的泛化,但它确实表明,需要更多的研究来了解继承的属性从SGD培训模式的使用是什么017年ICLR研讨会主题:
“深层网络不研究通过记忆”。
为什么说今天的报纸吗?
因为它的观点,另一个ICLR论文,之后谷歌大脑“理解深度学习需要重新考虑泛化”相互冲突的。本文由MIT Chiyuan张为第一作者,作者之一不乏丹尼尔的名字,如谷歌大脑萨米Bengio(是的,他是一个我们常说Bengio哥哥,头部的左侧图片图片——你不认为他们两个是兄弟?在谷歌),大脑的工作,现在是DeepMind研究员Oriol Vinyals。
值得一提的是,深度学习的理解需要反思概括这篇文章发布后,在学界引起了热烈的讨论和广泛的关注,本文根据Twitter上的讨论,ICLR得分高。
有人称为“必然会打乱了我们的理解深度学习”。
在文章“反思泛化”,研究人员通过实验发现:
有效的神经网络对整个数据集的暴力内存足够大。
即使是随机优化,过程也很简单。事实上,与真正的标签训练相比,随机标签训练时间增加了只有一个小的常数因子。
进行随机化的标签是一种数据转换、神经网络学习的所有其他属性相同的问题。
事实上,作者引入了两个新的定义“明确的”和“隐藏”正规化讨论深度学习。现在,根据两个正规化,Bengio实验室提出了相反的观点。
两大纸,谁对谁错,或者神经网络泛化能力的深度和强大的真正原因是什么?
让我们先从麻省理工学院,谷歌大脑和DeepMind合作”理解的深度推广神经网络需要思考”。
谷歌大片纸:理解深度学习,需要重新考虑泛化能力

提要
尽管巨大的体积,成功的深度人工神经网络的训练和测试可以显示一个很小的性能差异。过去一般认为泛化误差很小,光谱特征的模型或常规技术中使用的培训。
通过大量系统的实验中,我们用传统方法无法解释为什么在实践中大规模神经网络泛化性能。具体来说,我们使用随机梯度法证明了实验的训练,最先进的卷积网络用于图像分类随机标签很容易拟合训练数据。这种现象本质上是影响显式的正规化,即使我们取代真实图像的非结构化完全随机噪声,这现象会发生。我们使用理论结构证实这些实验结果,表明只要参数的数量多的实践数据点的数量,通常很简单,然而,这个定义的过程不涉及学习,或视觉上来说,我们可能不会用“信任”泛化误差的测量结果,因为我们认为如果该算法学习作为一个查找表(查找表具有良好的泛化性能),我们仍然认为信息是“记住”,而不是学习神经网络的深度已经完美的表达率的小样本(样本表达能力有限)。
通过比较与传统的模型来解释我们的结果。
1必要的背景知识:概述
人工神经网络的深度通常比他们有更多的训练样本训练模型参数。尽管如此,这些模型的一部分仍然显示了非常小的错误的形成,即训练误差和测试误差的区别。同时,自然模型架构也会坏泛化会非常容易 。那么,造成泛化好与坏之间的区别? 回答这个问题不仅有助于使神经网络更容易理解,而且还可以指导原则更丰富和更可靠的模型体系结构设计。
为了回答这个问题,统计学习理论提出了控制许多不同的泛化误差的复杂性度量方法(措施)复杂性。包括VC维(Vapnik,1998),随处复杂性(Bartlett &门德尔松,我们表明,有效容量固定的情况下,深层网络随机数据和真实数据,学习假说是不同的——真正的数据会更简单00(a)缺乏其他规范,早期停止可能提高泛化;),和统一的稳定(慕克吉et al。,2002;。Bousquet Elisseeff & 2002;。小山等。。,2004)。。
此外,当大量的参数,理论表明,需要某种形式的正规化,以确保泛化误差
如果伴随着早期停止,正则化也可以隐藏 。
我们的贡献。在这个工作中,通过论证它不能区分已完全不同的神经网络的泛化能力,我们质疑泛化的传统理解。随机化试验。我们的方法的核心是一个众所周知的非参数统计的随机测试变体(Edgington&Onghena,2007)
在第一组实验中,我们训练一些标准的副本数据结构,实际标签被随机的标签。
我们发现的核心可以概括为:。深层神经网络拟合随机标签很容易。更准确地说,当完全随机的真实数据标记训练,训练神经网络实现零误差。测试错误并不比随机概率,当然,因为培训没有标签和测试之间的相关性。换句话说,通过一个单独的标签随机化,我们可以力模型的泛化明显提升,在不改变模型的参数,尺寸,或优化器
我们训练CIFAR10和ImageNet分类基准不同的标准结构证实了这个事实
简而言之,从统计的角度学习,这款手表有一个深远的影响:。有效容量的整个数据集的神经网络强大的内存足够大;
即使随机标签的优化仍然容易。
事实上,比起那些真正的标签训练,训练时间增加了只有一个小的常数因子。。。随机化标签只是数据转换,所有其他的学习问题的本质没有改变。在第一组实验中,我们还用完全随机像素(例如高斯噪声)代替真实图像,并观察零误差的卷积神经网络拟合训练数据。这表明,无论他们的结构,卷积神经网络可以合适的随机噪声 。我们也改变数量的随机化,进一步增加顺利的情况下没有噪音,没有噪音。
这将导致一系列的中间学习问题,仍然存在一定程度的信号的标签。
噪音水平的提高,我们观察到的泛化误差不断恶化。这表明,神经网络在残余信号捕获数据,噪声同时使用强大的配件部分。下面我们将进一步详细讨论如何观察排除所有VC维,随处复杂性和均匀稳定性可以解释现有的神经网络泛化性能。显式规则化的作用
如果模型架构本身不是一个充分的正则化矩阵,它仍然可以显示明确的正规化多少帮助。
我们证明了正则化的显式形式,如减肥、数据丢失和增加,不能完全解释神经网络的泛化误差。换句话说:。显式规则化可以提高泛化性能,但是是必要的或不足以控制泛化误差。小样本的表达率。我们用理论结果补充我们的经验观察,显示大量的神经网络可以表示任何标记的训练数据。更正式,我们提出了一个非常简单的双ReLU网络,在p = 2 n + d参数,可以代表任何样本的大小为n d d标签。
利夫尼之后,et al。e。e。O(dn),取得了类似的结果。
虽然我们不可避免的两个网络的深度与宽度大,但我们仍然可以得到深度k网络,每一层只有O(n / k)参数。虽然以前的结果的表达率的神经网络可以在整个领域扮演什么角色,这一次我们专注于神经网络和有限样本的表达相关。与现有的函数空间的深度层不知道相反的(Delalleau&Bengio,2011;Eldan&Shamir,2011;Telgarsky,2016;Cohen&Shashua,2016),我们的研究结果表明,即使是2的线性尺寸的深度网络训练数据可以表示任何标签。隐式正则化的作用。虽然显式的正则化函数(比如辍学和体重——衰变)泛化可能不是必要的,但肯定不是全部拟合模型的训练数据泛化。事实上,神经网络,我们几乎总是选择模型的输出随机梯度下降法。采取线性模型,我们分析SGD作为隐式正则化函数 。对于线性模型,SGD总是收敛于一个最低标准的解决方案。
2.2
2
2。。。。。。Ademacher复杂性:数据集(X_1、。

。X_n)在某些假设类型H复杂性度量。平均而言,假设类H的复杂性测量数据拟合所有标签的可能性。
随机选择下面的部分,我们将使用这个AI创业竞争新情报10元,主流AI vc机构:蓝色项目,红杉资本中国基金,高瓴智慧到人工智能资本基金,湖蓝色,蓝色资本、IDG资本,榕树altissima,中信证券大厦,明潜在资本,松散颗粒远望基金发起主办的新智元,北京中关村科技园区管理委员会,在中关村科技园区海淀园管理委员会的支持,是一个聚合的AI技术领先和投资事件的领导人plextiy表明复杂性是不足以解释大型模型的成功
均匀稳定性:显示特定的模型来取代单个数据样本测量的敏感程度。重要的是要注意,这只是一个模型的属性,而不是数据本身的属性。随机化:。
第一个概念是“深层神经网络拟合容易随机标签”。基本上,我们可以做任何群输出,输入装置,实现零误差。这使我们得出结论,一个足够大的DNN可以简单地使用暴力来拟合数据记忆。
即使在数据与不同程度的随机性,仍然能够适应模型。随着量的增加噪声的随机、泛化(测试错误-培训)开始增加。这意味着模型学习找出应该保留在数据信号,并使用内存来拟合的噪音。

我们使用的数据测试几个层次的随机性,网络可以完全拟合训练中。然而,随着越来越多的随机插入,花更多的时间目标函数
这主要是由于大误差反向传播引起的质量参数的梯度更新。图1:CIFAR10随机随机像素标记和配件。
(一个)显示不同的实验装置损失下的训练训练步骤恶化情况;。。(b)展示了一个不同的标签腐败要求相应的收敛时间。(C)显示不同的标签的堕落下测试误差(0训练误差,所以它也是泛化误差)。
在这些实验中需要注意的是,这只是一个数据变化
本文使用随机实验排除推广成功的可能的原因,比如随处复杂性和均匀稳定。我们可以排除复杂性度量,比如随处因为我们是完全模型拟合训练数据(R(H)= 1),因此,。我们不能使用一致收敛边界作为解释低泛化误差的原因。我们不能用稳定措施,因为变化是数据而不是任何模型参数。
正则化:。第二个概念是“显式的正则化可以提高泛化性能,但需要控制泛化误差”。正则化技术可以推广到帮助调整参数泛化,但对于低测试错误不是必需的。

考虑正则化的角色的一个好方法是考虑假设空间
通过使用regulizer,我们本质上可能的假设空间降低到一个更小的子集。本文试图明确正规化的三种类型:数据增加,体重衰变和辍学。作者发现数据增加和体重衰变有助于减少测试误差,但即使没有使用模型还可以推广。
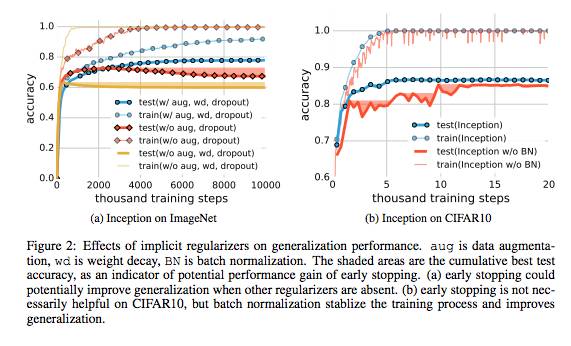
(注:体重衰变,而增加的数据非常有用,也就是说,数据是最好的调整)。表2显示了Imagenet标签和随机标签当他们的实际表现。作者尝试了各种形式的隐式正则化,比如早期停止和批处理标准化。
对于这两种技术,泛化误差的情况下不使用这项技术只有少量的减少
这使得作者可以得出这样的结论:“规范的根源不能泛化”。图2:隐式正则化对泛化性能的影响。
8月是数据增加,wd体重衰变,BN批正常化。D)来代替一些数据集的一部分
CIFAR10(b),早期基本没有停下来提供帮助,但批标准化稳定的训练过程,提高泛化。小样本的表达率。文章发现证据表明“ReLU激活和2 n + d重量的两层神经网络,它可以表示样本大小为n d d任何函数”的定理。真的显示任何数据集的神经网络强大的能力(强力)。
我。。结论。传统的机器学习的概念基于合同(精简)。在几乎任何公式,学习归结为从数据中提取低复杂性的模型。
暴力内存通常不被认为是一种有效的学习。同时,它可能是纯粹的记忆在某种程度上是一种有效的策略来解决问题的自然的任务。
我们的研究结果挑战了传统机器学习的理解,并展示了许多成功的神经网络有效地很容易有一个纯粹的记忆能力

这让我们相信,这些模型的治疗问题用来训练时可以充分利用大量的内存
可能在传统意义上的研究仍然是部分发生,但它似乎有很多记忆密切相关因此,传统的方法不适合推理为什么这些模型可以很好的概括我们认为,理解神经网络需要重新考虑泛化。我们希望我们的论文只是一个开始,挑战传统观念,指向未解决的问题。Bengio实验室观点:深层网络不学习记忆。在这篇文章中,。
1。1
训练数据来实现其良好的性能事实上,神经网络学习的深度是一种简单和有限的假设数据样本为了支持这一观点,我们建立一个神经网络学习定性差异与自然噪声数据集,表明:(1)需要更多合适的噪声能力;。(2)随机标记收敛时间较长,但随机输入的收敛时间短;。(,论文提出的方法进行了测试(如本文所示))在实际数据样本训练DNN学习函数,比噪声数据更简单的培训,简单的评估标准,当损失函数收敛的清晰度。g。g。1。1。介绍。
泛化(泛化)测量?训练在一个给定的数据集。模型从未见过在前面的数据上运行的能力,这些数据和训练数据未见相同的底层分布。泛化的传统观点是,容量足够大(如参数的数量大于训练样本的数量)的模型中,“记住”每个样本的表达,这是一个适合一个训练集,导致在测试集验证或可怜的泛化。但是,这种观点相反,深层神经网络(DNN)比训练样本通常包含多个参数,但表现出良好的泛化性能。张等。
谷歌最近的工作(2017年,如上所述纸)发现,传统方法不能解释DNN这种性质。他们提出DNN可以适应随机噪声,并认为部分原因是深层网络可以用来研究通过“集体记忆”我们认为并非如此,通过显示随机噪声和学习之间的数据支持我们的观点不同。“记住”训练集是什么意思。e。e。
训练误差接近零)。看起来那么回事,但不完全,直观地说,“记住”数据的算法应该是有限的训练集在某种程度上,一个查找表这导致了另一种解释;训练误差和随机泛化误差为零。根据这个定义,DNN不会记忆。
2。2
不是在学习模式。在实验和讨论,研究人员使用一种噪音(随机标签或我我。能力的理论模型。
有效的能力。受两个因素的限制:大小和培训时间(更新)的数据集。

2.2。

测试和讨论。i。。
3。3
然后我做高斯噪声输入(均值和方差匹配实际数据)。第一个发现(见图1),随着越来越多的样品替换为噪声,DNN需要更多的能力来实现最高的性能。这表明网络更简单的模式,这是更少的参数解释真正的数据。
减少数据集的容量或增加数据集的大小会降低培训的实际数据和噪声
实验2(图2),然而,表明实际数据的影响不明显?
基于正则化学习的影响的分析,研究人员发现,与(Zhang et al,2017)发现,如果您正在使用一个随机标签训练,正规化(比如辍学和高斯噪声)可以限制的训练精度。研究人员使用Zhang et al。
⊥17
3
结论。我们研究记忆的经验探索表明,噪声的研究和实际数据是不同的?在有效容量相同的情况下,学习DNN真实数据时使用更简单的比学习时噪声的假设。e。e
通过阻断记忆的能力)。* * *。深度的真正原因是神经网络泛化能力和强大的。欢迎留下您的分析
【新智元公共数字,对话框中输入“170219”下载论文】。的资源
https://openreview。Net/03530年。Id = rJv6ZgHYg
https://arxiv
Org/PDF / 1611
PDF。PDF。https://theneuralperspective。Com / 2017/01/24 /理解-深-学习-需要-一个泛化/。https://medium
Com/intuitionmachine/an -归纳- -深-学习- ec66ed684ace #。3 cycyk87b。
独角兽】【寻找人工智能新智慧元联手十大资本 启动2017年创业大赛。com。comhttp://form。mikecrm。
Com/gthejw
